
Project Overview
The client required a scalable and cost-effective solution to consolidate data from multiple sources into a centralized analytics platform. As the organization was new to the data engineering ecosystem, they needed a platform that was simple to implement, required minimal infrastructure management, and supported multiple data ingestion patterns.
United Techno implemented Rivery, a cloud-based SaaS data integration and orchestration platform, to automate data ingestion and pipeline management. Data from various sources including on-premise systems, APIs, and SFTP/FTP servers was integrated and centralized into Azure SQL Database to support reporting and analytics. The solution provided an efficient framework for automated pipeline orchestration, transformations, and workflow scheduling across environments.
Business Challenges
Multiple Data Sources – The organization needed to ingest data from various sources including on-premise databases, external APIs, and file-based systems such as SFTP and FTP servers. Managing these integrations manually created delays and operational complexity.
Lack of Data Engineering Infrastructure – The organization did not have an established data engineering platform to build and manage automated data pipelines, making it difficult to consolidate and process data efficiently.
Manual Data Processing – Many data ingestion and transformation processes were performed manually, leading to delayed reporting cycles and increasing the risk of human errors.
High Cost of Traditional Platforms – Enterprise ETL platforms typically require significant infrastructure investment and specialized engineering expertise. The client required a cost-efficient platform that could be implemented quickly.
Deployment and Environment Management – Managing multiple environments such as Development, Testing, and Production required a simplified deployment process without building complex CI/CD infrastructure.
Solution Approach
Cloud-Based Data Integration Platform – A modern SaaS-based data integration platform was implemented to automate data ingestion, transformation, and pipeline orchestration. The platform enabled the organization to build and manage pipelines efficiently without maintaining infrastructure.
Integrated Data Ingestion – Data was ingested from multiple enterprise sources including On-premise databases, External APIs, SFTP / FTP servers, Flat files and third-party application exports and this approach allowed the organization to consolidate data from different systems into a unified analytics environment.
Automated Pipeline Orchestration – Automated workflows were implemented to manage data ingestion, scheduling, and pipeline execution. These pipelines ensured that data could be processed and delivered consistently without manual intervention.
Data Transformation and Standardization – Custom transformation logic was used to clean, structure, and standardize incoming datasets. Business rules were applied to ensure consistent data formatting and quality before loading into the target system.
Centralized Data Storage – Processed data was loaded into a centralized analytics database, creating a single source of truth for reporting, analytics, and business applications.
Simplified Environment Management – The platform enabled seamless management of Development, Testing, and Production environments. Pipelines could be easily promoted across environments, reducing deployment complexity and improving release cycles.
Business Impact and Outcomes
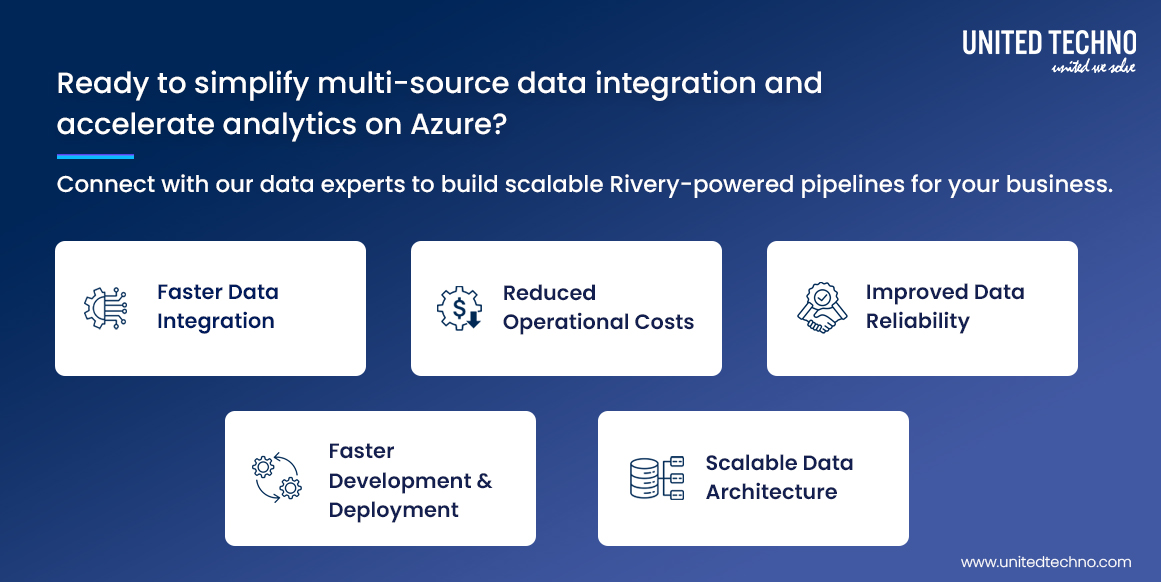
Faster Data Integration – Data integration efficiency improved by approximately 40%, enabling faster reporting and insights.
Reduced Operational Costs – Operational costs decreased by approximately 35–45% compared to traditional ETL infrastructure.
Improved Data Reliability – Automated orchestration and standardized pipelines improved the consistency of data processing and Data reliability improved by approximately 50–60%
Faster Development and Deployment – Simplified pipeline development and built-in environment management accelerated the development lifecycle and Pipeline deployment became 60–70% faster.
Scalable Data Architecture – The architecture allows new data sources to be integrated easily without significant changes to the platform.
Conclusion
The implementation enabled the client to establish a modern data integration framework without the complexity of traditional data engineering infrastructure. By leveraging a cloud-native data integration platform, the organization automated data ingestion, transformation, and orchestration processes.
The centralized analytics architecture improved operational efficiency, reduced infrastructure costs, and enhanced data reliability. This solution now provides a scalable data foundation that supports ongoing analytics initiatives and future business growth.